
ScreencastsONLINE just continues to pay dividends for me in my Apple-device-filled life. In this case, it was a brand new tutorial for a utility that I have known about for a long time: PopClip.
PopClip is a Mac utility that adds a floating action menu whenever you select text, making common actions like copy, paste, search, and share faster. It’s especially useful if you work with text a lot and want quick, mouse-driven shortcuts
If you are a Windows user but intrigued by this idea, there's hope for you yet. For Windows users, SnipDo is the closest thing to PopClip I'm aware of. It’s the best match if you want the same “select text, then get actions” workflow, though I haven't tried it before.
Dave had mentioned something to me about PopClip recently (that he was thinking about getting into it). And lo and behold, here comes the update for the latest videos on screencasts online. And there was one about PopClip. I watched it and was ready to dive in and play.
Lee made it super easy to understand how it works and how to customize it to your liking. Here are the topics that Lee covers in the PopClip Updates Screencasts Online tutorial, in case you're interested:
- PopClip Overview
- Installing Extensions
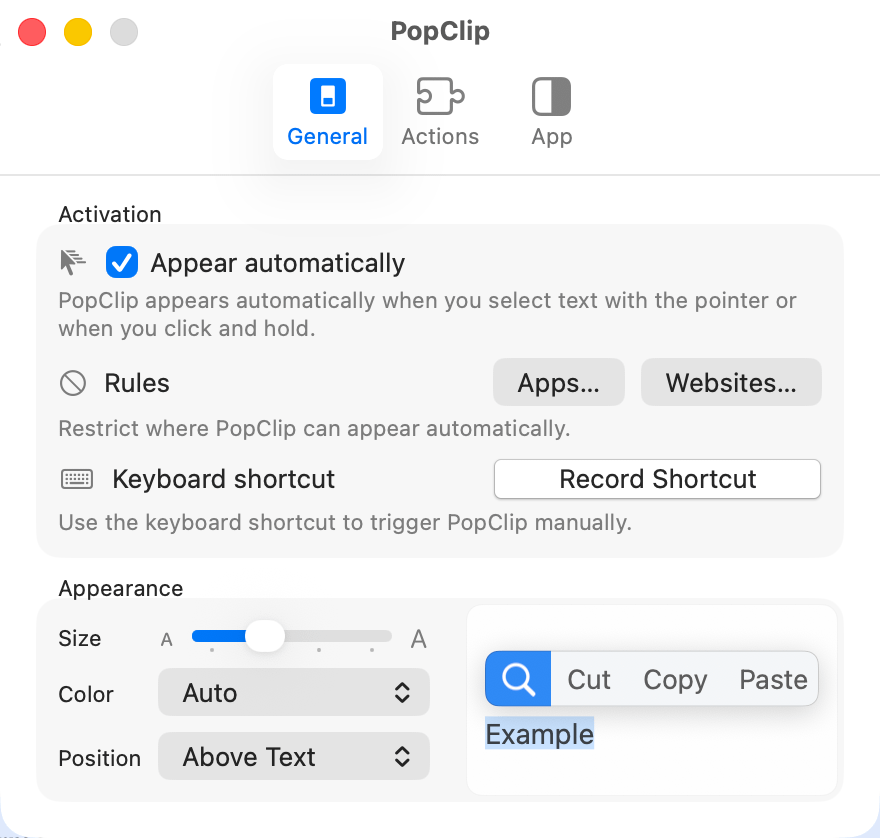
- PopClip Settings
- Obsidian Extension
- Perplexity Extension
- ChatGPT Extension
- Open In Browser Extension
I have access to PopClip as part of my SetApp (ref link) subscription, but it is also available on their website to buy as either a standard or lifetime PopClip license.
Past Concerns About PopClip No Longer Are An Issue
I'm unclear at this point whether PopClip has changed a lot since I looked at it or whether I just never understood how it worked in the first place. No matter my concerns about it have been resolved as follows.
Popping Up When Not Needed
I remember years ago, downloading it and playing with it and instantly deciding it got in the way of my internet reading habit of constantly clicking and dragging across text as I read it. That often helps me focus when needing to consume something dense or otherwise hard to discern. I've learned I'm not alone on that click and drag habit, by the way, but now PopClip seems to be ready for someone like me to tap into the power of what it has to offer, while still getting to keep my pattern of doing this.
You have granular controls over where pop clip appears once you you click and drag across text and release your mouse or trackpad. You can determine if you want PopClip to appear automatically. Even after about 15 minutes of experimentation, I would say leaving this as the default really helps you leverage the real power of PopClip but if you had certain websites that you visited where it wasn't going to be particularly helpful you can have rules set up where it gets disabled based on a specific app, such as a browser, or specific websites that you would like to disable it on. I haven't done that again because of the controls under appearance. you can change the size of the pop clip as it pops up or you can change the color or whether or not it gets positioned above or below the text.
Getting carried away with extensions
Another concern I had was being so inspired by all these different possibilities that I got carried away and installed a bunch of extensions that would then do away with the simplicity of PopClip. As I look at my installed PopClip extensions right now, after only having the app for less than an hour, I've got 15 different actions. However what I'm realizing because of the ScreencastsONLINE tutorial I watched is that not all of the actions appear every single time pop clip may be evoked.
PopClip is context specific and only brings up the relevant actions for what you're in the middle of doing. A simple example of this is that spell check is only going to come up when you've selected a word that is misspelled. Otherwise, it remains in the background, invisible to you. You can also configure the order that your extensions appear such that your more commonly used ones are closer to the front of the line.
This 5-minute YouTube preview video of Lee's ScreencastsONLINE tutorial gives you a look at the extensions he suggests in the tutorial and is well worth a watch.
Early Experimentations
Installing PopClip and getting started was a breeze. This is particularly the case because of it being part of my SetApp subscription, as I mentioned earlier. The built-in actions are all easy to use and understand. I think if it were only the case that I would be offered easier ways to cut, copy, and paste, however, I probably would have skipped PopClip, entirely. Those basic keyboard shortcuts have been burned in my brain a long time. That said, PopClip has a lot more to offer than just those essentials. The other nice thing is it doesn't take long at all to both learn and to begin to get some of the features and functions into one's muscle memory.
Here's a bulleted list of some of the PopClip actions I think could be potentially potentially particularly helpful for my use cases. I'm sure I'll be finding more as well.
- Open link: In working with various LLMs and also coming across this issue in other cases, I find sometimes a link is presented to me but is not clickable. All I have to do with pop clip is select the text to activate pop clip or use the keyboard board shortcut I have established, and then I'm able to use this pop clip action to easily open the website. site. This was very easy to install and understand from the beginning.
- Title Case and Uppercase: These two functions are things I don't do that often, but when I do, I have to open up an entirely a separate app and try to remember how to use it. It's typically been so long. Now I can easily select text and have it modified in less than a second or two using these two actions.
- Timestamp: This one is also super simple, but will save me a ton of time. Anytime I attend a conference or go to a meeting, I always have the file name begin with a four-digit year followed by a dash, a two-digit month followed by a dash, by, you guessed it, a two-digit day. and now that's just going to be a simple muscle memory thing for me that I'll be able to pull up much faster than me sitting there trying to type it despite how fast I type on my 10 key. I can now get something like this in less than a second or two: 2026-04-10.
- Perplexity App: I have not been a big user of perplexity, but many people I highly regard do make use of it, this seemed an easy way to have other options when experimenting with artificial intelligence and wanting to see how its approach to a given prompt might vary from the others I use more frequently.
This is the first piece of writing I have done since installing PopClip and can already ready tell that it is not only not going to get in my way, it's going to be a tremendous his help to me. I imagine there are many more pop clip actions in my future.
One last thing I wanted to mention is I was talking earlier about getting PopClip into to my muscle memory, that's such a big part of computing for me. When watching Lee describe how he uses PopClip, He mentioned using command L to highlight the URL for the website he's currently on. I delighted when I saw that since that's something I do a gazillion times per day, but do not have that keyboard shortcut in my muscle memory. I have since added it to my keyboard shortcuts that I keep in the Tot App by the Icon Factory, so that as I'm learning new ones, I can remember to practice them and instill them into my habits.



